project
【事例】 マーケティング効果検証のデータサイエンス実務から見えた課題と解決策~実効性のあるPDCAを回すために~
- 小売業
-
 シェア
シェア
-
URLをコピーしました

Introduction
企業活動、特にマーケティング領域においては、PDCAを高速に回し、より効率良くアクションするための研究と実行が日夜続いている。昨今ではデータの活用、業務フローのシステム化によって、さらに効率と精度を上げたPDCAを実現する企業も多くなった。
一方で、膨大なデータからPDCAを回すためには専門知識や高い技術力が必要となる。同時に、正確な課題の認識、ビジネスとしての重要性も設計に組み込みながら構築する必要がある。
アポロでは、マーケティングの現場でこのようなシステム導入〜実装までを行ってきた。今回は、アポロのデータサイエンティストとして手を動かす現場の声を紹介する。
PDCAサイクルと、客観的なCheck (効果検証) の重要性
PDCAサイクルとは、Plan(計画)-Do(実行)-Check(評価)-Act(改善)の頭文字をとったフレームワークの一つで、物事を効率良く、よりよいものにするためには欠かせない概念である。特に企業においては、常に利益を最大化することを考えてPDCAを実行する。
このPDCAサイクルをより正確に、より強力に、より迅速に行うために、ID-POS(会員情報が紐づいたレシート情報)やMA(Marketing Autmation)ツールを組み合わせて、配信自動化、配信結果の即時反映などが行われている。
例えば、小売業界では特定の会員にのみクーポンを配り(Plan-Do)、売上があがるか検証(Check)、次のクーポンの金額や送付先を再考して再実行(Act)する 、といったことが行われてる。そして現在では計算機の発展や、会員プログラムの強力なシナジーにより、顧客データをデータベースとして蓄え、分析し、PDCAを回している。
その中でも最も重要なことは、チェックの高度化と、データによって著しく向上した次へのアクションである。

これまで肌感覚だったものが定量評価に変わり、データが無かった時代に比べて、施策の効果とその変化を確実に把握できるようになった。その一方で、データの収集や検証をする際に、常に気をつけなければならないのは『バイアス』である。
私たちの選択を間違えさせるバイアス
バイアス(bias) とは先入観や偏見という意味の言葉である。
例えば、水が入ったコップを見て、コップの中身はいっぱいだという表現はバイアスだ。人を介した主観だけでは、いっぱいという言葉の意味が、コップの8割なのか、それともフチぎりぎりまで満たされているのかは、それぞれの感じ方やシチュエーションによって変わる。
ほかにも次のような例が考えられる。
中身が見えない袋に、ボールがたくさん入っていることを思い浮かべてみる。その袋に手を入れ、ボールをいくつか取ったところ、出てきたのはすべて赤色だった。
この情報を知った多くの人は、袋の中身は全部赤色であると確信、または期待をする。
だが実際には、袋には赤だけでなく、青や黄色など、他の色のボールがあるかもしれない。
これはセレクションバイアスと呼ばれる、選んだものが特定の偏りを持つことで生まれるバイアスの一種だ。このように私たちの認知や行動はバイアスによって、事実を曲解してしまったり、それによって行動も変わる可能性がある。
だからこそデータサイエンティストとしては、データを扱う際には、様々なバイアスを取り除き、偏見がない、誰がどう見てもそう思える効果検証をしなければならない。そうすることで初めて、これまで効果があると思って取り組んできたマーケティング施策について変更する勇気が持てない、変えることについて上長を説得できないというマーケ―ターに対して、”変えないことを否定する根拠”を、偏見のないデータ分析結果をもとに自信を持って提言できるようになってもららうことができ、実際に効果的なPDCAサイクルを回すことができる。
効果検証を正しく行う = バイアスをいかに除くか
効果検証を正しく行うためには、
- 全く”同じ”対象に
- 全く”同じ”処理をし
- 全く”同じ”方法で観測し
- 全く”同じ”方法で検証し
- 全く”同じ”に検証する
ことが必要になる。この”同じ”を作る各ステップで、常にバイアスが生じてしまう。
例えば販売促進のためにクーポンを配るとして、その配る対象を全く同じにすることはできない。誰一人として全てが同じ人はいないからである。
だからこそ、できる限り似た属性の人をさがし、クーポンを配る対象・配らない対象を絞り込むことが重要だ。
時間や時期をずらして同じ対象者にクーポンを配ったとしても、初めてクーポンをもらった対象者と、1度クーポンを使用した対象者では、属性が変化して同じ対象とは言えなくなってしまう。
他にも、“全く同じ”という処理についても考えてみよう。
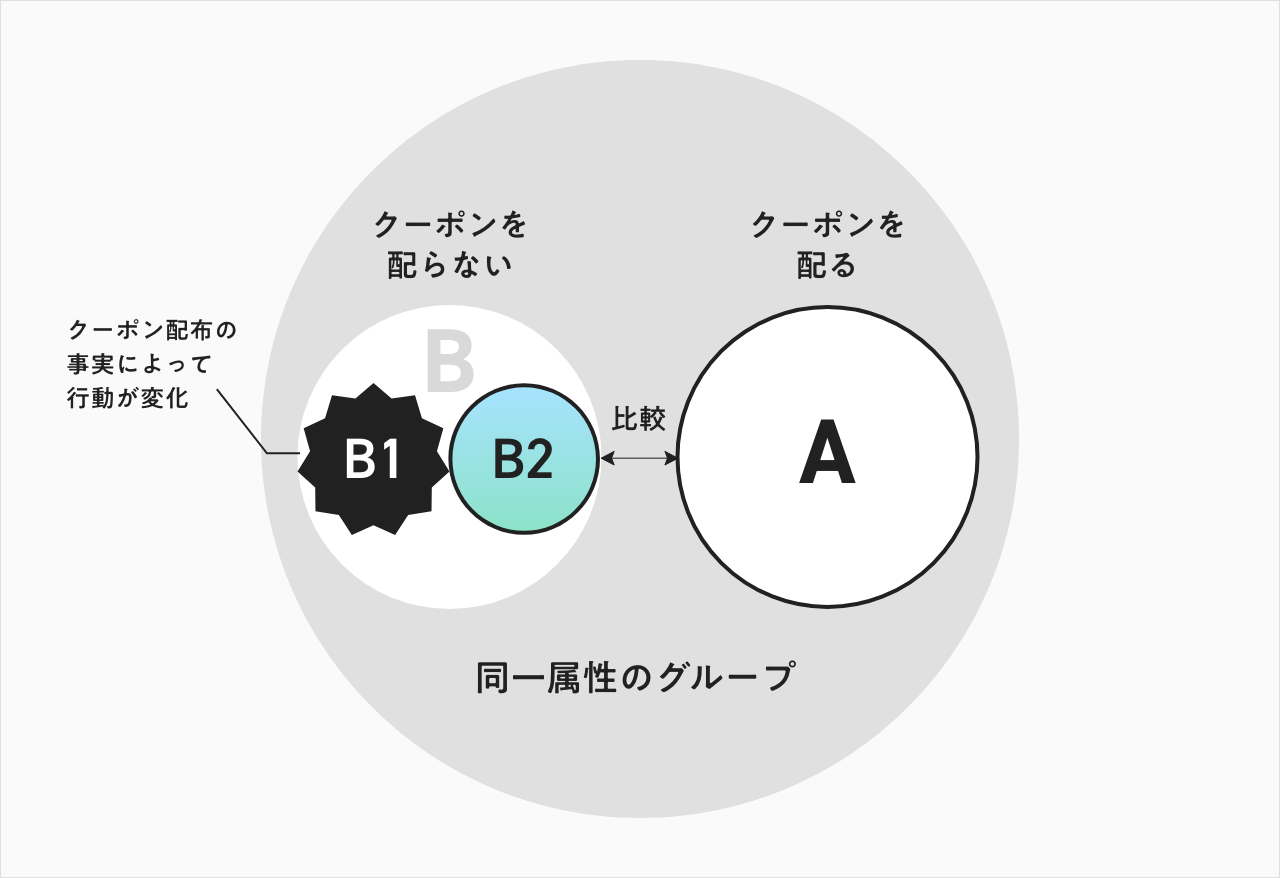
先ほどのクーポンの例で、できるかぎり属性の似た母集団を用意し、 クーポンを配るグループ(A)と、配らないグループ(B)に分けると仮定する。

このような検証の仕方はABテストと呼ばれるが、ここにも罠が潜んでいる。なぜなら、配る・配らないがすでに同じものではない以上、『配らない』という事象がBグループに影響を及ぼす可能性があるからだ。
Bの中には、Aにクーポンが配られることを知っている+自分は配られていない人(B1)と、 Aに配られることを知らない人(B2) があり得る。
B1はクーポンがあることを知っているため、それを持っていないにも関わらず買う、という選択がしづらくなる。クーポンを誰にも配らなかった時に比べ、B1の売上が落ちてしまう可能性が生まれる。
真に正しく比較するためには、まずBの中で、Aにクーポンを配ったときに、B1とB2の変化が同じであることを担保し、そのうえでAとBの比較をすることで、初めてクーポンの効果を検証ができる。
上述した例で、B1とB2の変化が無いと仮定することを『並行トレンド仮定』と呼ぶ。効果検証では、その並行トレンドを常に担保することがとても重要なファクターだ。
実務でいかに並行トレンドを保証するか
果たしてB1とB2をどのように見分け、クーポンを配らないBグループの並行トレンドを保証するのか。
B1=B2となる集団を結果から選べば因果関係が逆になり、セレクションバイアスがかかる。かといって事前にアンケートを取るようなアクションを取っても、Bが介入される状態になってしまい、正確な検証が行えない。
それでも、介入されない比較対象グループを事前に用意できる場合は、まだいい方だ。
実務ではABテストの実施すらできないケースがあり、そういった際に、どのような検証が行えるのかを私たちは常に考えなければならない。これまでの課題に対して唯一の答えはないが、統計学や機械学習を用いることで、ある程度解決できる場合もある。
本記事では、効果検証を正しく行うためには、いかにバイアスを除き、比較がしやすいデータを用意することの重要性について説明した。
次回は、実際の現場で効果検証を行う際の手法や、その応用法を詳しく紹介する。

Share
-
シェア
-
URLをコピーしました